Enquire Now
Built for Teams Who
Can't Afford Downtime

Whether you are running a lean IT team or managing global operations, our outsourced NOC services scale to fit your needs. From SMBs to large enterprises, we deliver consistent uptime, real-time visibility, and proactive monitoring to keep your network always available.
-
 Real Estate
Real Estate
-
 Finance & Loans
Finance & Loans
-
 Healthcare
Healthcare
-
 Education
Education
-
 Insurance
Insurance
-
 Hospitality & Travel
Hospitality & Travel
-
 Manufacturing
Manufacturing
-
 Legal Services
Legal Services
-
 Automobile Industry
Automobile Industry
-
 Marketing Agency
Marketing Agency
-
 Consulting Services
Consulting Services
-
 SMEs & MSMEs
SMEs & MSMEs
-
 B2B & D2C
B2B & D2C
-
 Nonprofits
Nonprofits
-
 Fitness & Wellness
Fitness & Wellness
What Makes Our Network Operations Center (NOC) Services Different from Traditional Monitoring Solutions
Our AI-powered NOC delivers more than just monitoring. It combines real-time visibility, predictive analytics, automation, and compliance tracking into one powerful ecosystem. Designed for SMBs, enterprises, and service providers alike, our NOC ensures 24/7 uptime, faster incident resolution, and proactive IT infrastructure management so your business stays secure, scalable, and always connected.
-
 Real-Time Network Monitoring
Real-Time Network Monitoring
-
 Automated Incident Detection
Automated Incident Detection
-
 Predictive Analytics & Forecasting
Predictive Analytics & Forecasting
-
 SLA & Compliance Tracking
SLA & Compliance Tracking
-
 Device Health Monitoring
Device Health Monitoring
-
 AI-Powered Root Cause Analysis
AI-Powered Root Cause Analysis
-
 Customizable Dashboards
Customizable Dashboards
-
 Multi-Vendor Device Support
Multi-Vendor Device Support -
 Alert Noise Reduction & Smart Routing
Alert Noise Reduction & Smart Routing -
 Automated Incident Resolution
Automated Incident Resolution
-
 Centralized Operations Console
Centralized Operations Console
-
ITSM & Cloud Integrations
Continuous visibility across your IT infrastructure
See every device, application, and link in action with live visibility. Spot performance bottlenecks, bandwidth spikes, and outages as they happen. Stay in control of your entire network from one screen.

Features:
- Visibility
- Uptime
- Performance
- Control
- Proactivity
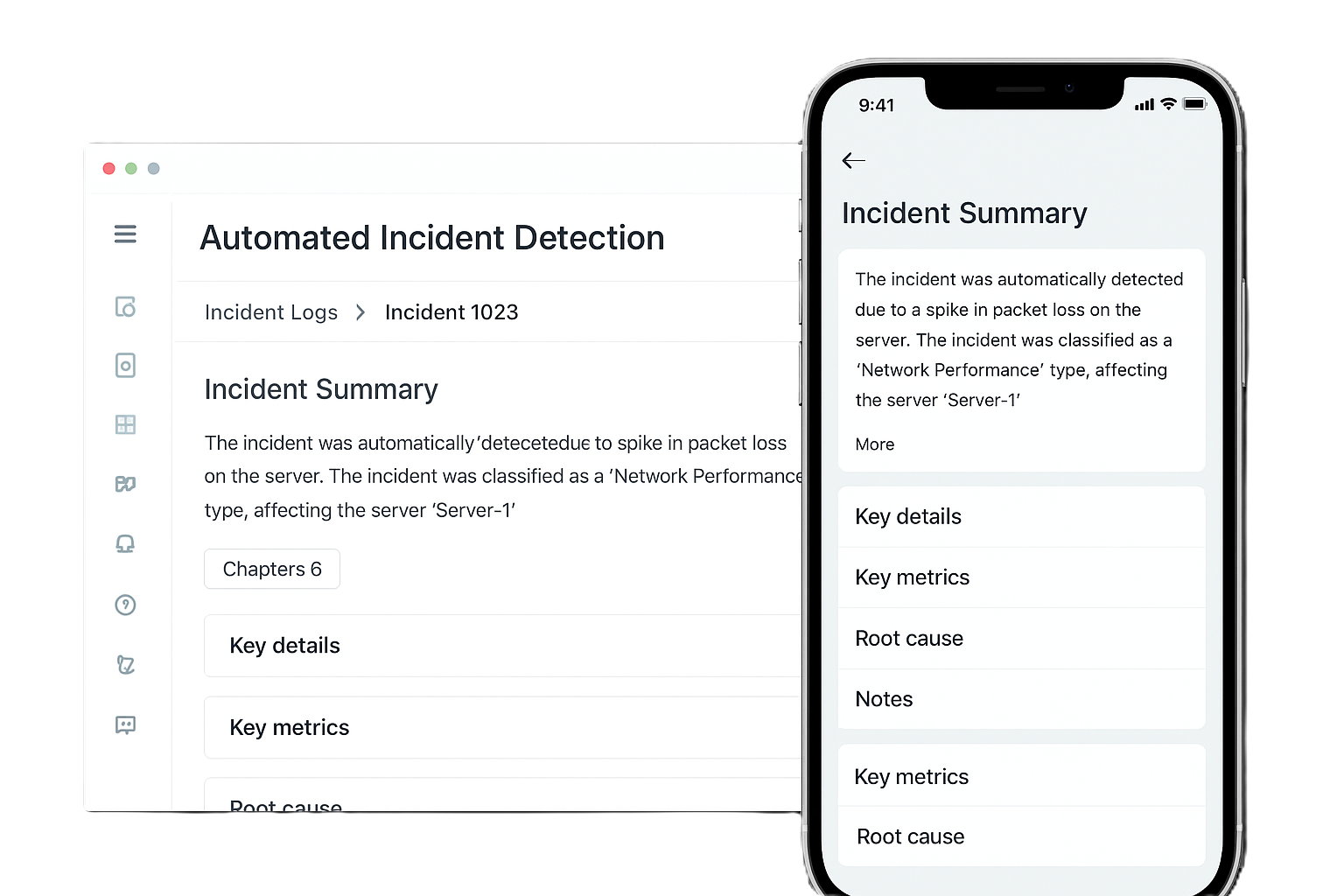
Instant alerts for faster response
Stop chasing tickets manually. Our system flags anomalies and outages instantly, creating alerts the moment issues appear. Be the first to know, not the last to react.
Features:
- Speed
- Accuracy
- Alerts
- Reliability
- Efficiency
Stay ahead with AI-driven insights
AI-driven insights help you forecast capacity needs and potential failures. Plan upgrades before bottlenecks slow you down and prevent downtime with proactive decisions.
Features:
- Insights
- Prevention
- Trends
- Optimization
- Planning
Simplify audits and prove accountability
Keep service level agreements and compliance obligations on track automatically. Generate ready-to-share reports for audits and client reviews, without digging through logs.
Features:
- Reporting
- Accountability
- Transparency
- Governance
- Assurance
Prevent outages with proactive device care
Track CPU usage, memory, storage, and temperature across routers, switches, firewalls, and servers. Spot unhealthy devices early and extend hardware life with preventive care.
Features:
- Stability
- Maintenance
- Prevention
- Endurance
- Reliability
Cut through noise to find the real issue
Eliminate alert storms and false positives. Our AI engine filters noise and points you directly to the source of a problem, cutting resolution time dramatically.
Features:
- Intelligence
- Precision
- Clarity
- Resolution
- Speed
Role-based views for smarter decisions
Design dashboards that fit your priorities. Focus on uptime metrics, SLA performance, or critical device health—all tailored to what your team needs to see.
Features:
- Flexibility
- Personalization
- Simplicity
- Focus
- Usability
Unified management across all vendors
No matter which vendor your hardware comes from, manage it in one unified console. Simplify operations across mixed environments without juggling multiple tools.
Features:
- Compatibility
- Integration
- Standardization
- Simplicity
- Scalability
Eliminate alert fatigue with intelligent routing
Cut through the flood of alerts with AI-based filtering. Deliver the right alerts to the right teams instantly, reducing fatigue and speeding up incident response.
Features:
- Filtering
- Relevance
- Accuracy
- Prioritization
- Productivity
Resolve common issues in seconds
Automate routine fixes like service restarts, device reboots, and traffic failovers. Resolve common problems without human intervention and reduce mean time to repair (MTTR).
Features:
- Automation
- Speed
- Continuity
- Consistency
- Recovery
One control center for your IT operations
Unify tickets, logs, alerts, and analytics into one shared view. Break silos across teams and let everyone work with the same real-time data.
Features:
- Unity
- Collaboration
- Transparency
- Control
- Simplicity
Seamless connectivity with ITSM and cloud tools
Plug into ServiceNow, Jira, AWS, Azure, Google Cloud, and more. Keep your NOC tightly connected with your existing IT workflows and cloud ecosystems.
Features:
- Connectivity
- Workflow
- Efficiency
- Automation
- Ecosystem
Essential Facts About Cybersecurity and Network Operations Centers (NOC)

Cyber threats are growing at an alarming pace, yet many businesses still underestimate the risks and the role of a NOC in preventing them. From ransomware losses to delayed breach detection, the facts show why proactive monitoring is no longer optional. Our myth-busting insights reveal how NOC services empower even SMBs to stay secure, compliant, and resilient against today' s cyberattacks.
Calculate Your Security Score
NOC Myths vs Reality: Breaking Common Misconceptions About Network Operations Center Services
Many businesses still believe NOC solutions are expensive, complex, or only meant for large enterprises. The truth is, modern outsourced NOC services are affordable, scalable, and built to deliver 24/7 monitoring, automation, and compliance for companies of any size.
My Business Need NOC?
NOC Myths vs Reality:
"Uncover the truth behind common misconceptions and see how modern NOC services deliver cost-effective, scalable, and reliable network operations for every business."
Myth
NOC is only for large enterprises.
Reality
Modern NOC services are scalable for SMBs and mid-size companies.
Outsourced NOC is always costly
Outsourced NOC reduces infra, staffing, and tool costs by up to 50%
In-house NOC gives more control.
Outsourced NOC offers better visibility, 24/7 coverage, and expert monitoring
NOC is just about monitoring
A true NOC covers monitoring, automation, compliance, and incident resolution.
Automation replaces people.
Automation frees your team from repetitive tasks so they can focus on strategy.
Implementing NOC takes months.
Our NOC can be deployed in under 30 minutes
In-House NOC vs Outsourced NOC
(Comparison Table)
Feature / Benefit
Setup Cost
Monthly Pricing
Staffing & Expertise
Scalability
Incident Detection
Response Time
Hidden Costs
Security & Compliance
Customization
Reliability
Inhouse NOC
Very high (infra, tools, staff)
7-10 Lakhs
Requires hiring and training, turnover issues
Limited, infra upgrades required
Depends on manual monitoring
Slower due to limited staff
High (salaries, infra, licenses)
Often inconsistent updates
Limited by internal resources
Staff fatigue, downtime risk
Outsourced NOC
Low, no infra required
2-3 Lakhs
24/7 certified NOC engineers included
Flexible, scale up or down instantly
AI-powered instant detection
Fast, proactive response 24/7
None, transparent pricing
Compliance-ready, audit-friendly
Tailored dashboards & workflows
Always-on monitoring, 99.99% uptime
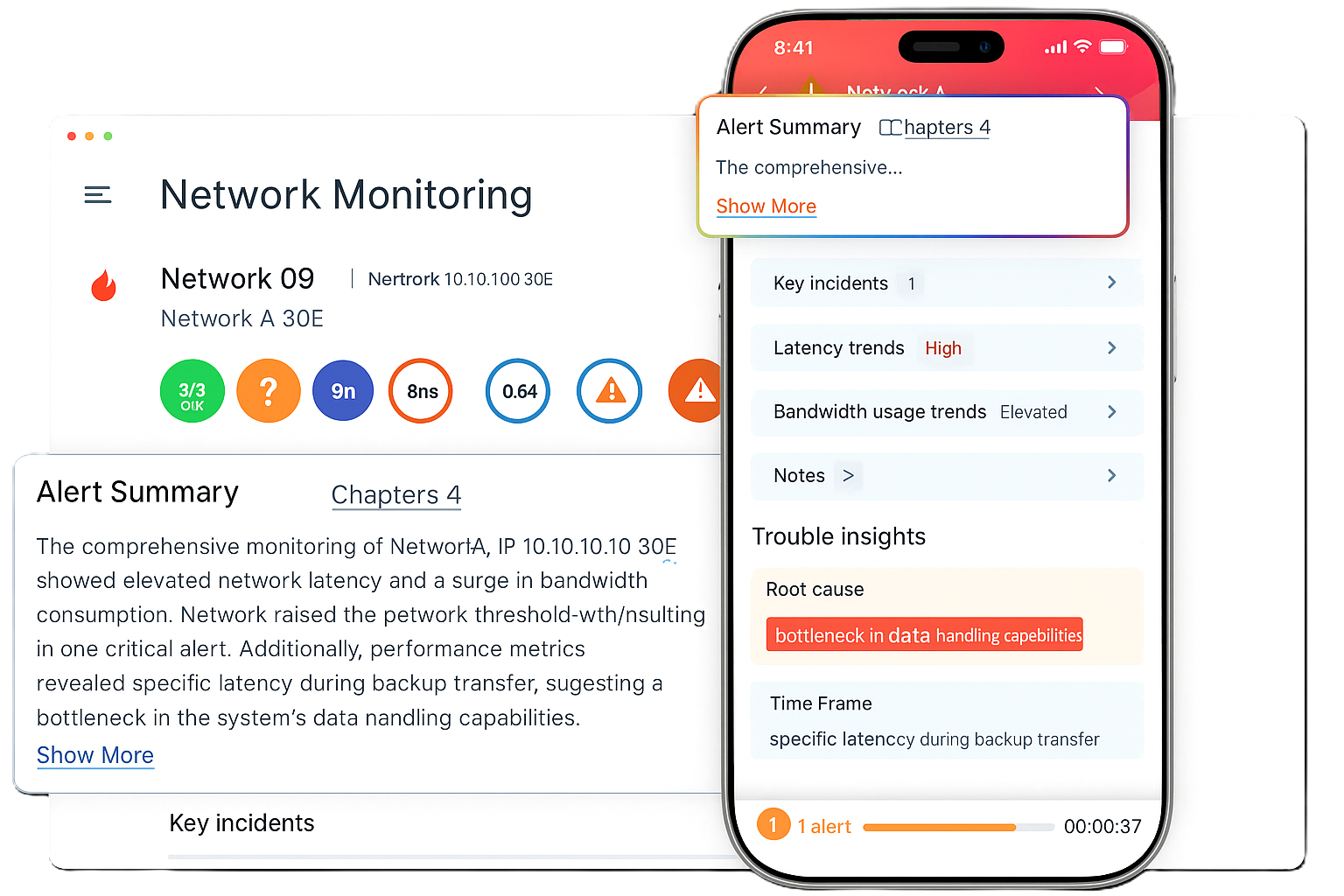
Real-Time Network Monitoring
Stay on top of your entire IT infrastructure with live monitoring of devices, applications, and connections. Our NOC keeps an eye on uptime, bandwidth, latency, and performance at all times. You shall know instantly if something goes wrong, from a router failure to a service slowdown. With a single unified dashboard, there no more switching between tools. Proactive alerts ensure you respond before users even notice a disruption. Real-time visibility means complete control and confidence in your network health.
Real-Time Network Monitoring
Stay on top of your entire IT infrastructure with live monitoring of devices, applications, and connections. Our NOC keeps an eye on uptime, bandwidth, latency, and performance at all times. You shall know instantly if something goes wrong, from a router failure to a service slowdown. With a single unified dashboard, there no more switching between tools. Proactive alerts ensure you respond before users even notice a disruption. Real-time visibility means complete control and confidence in your network health.
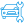
Automated Incident Detection
Manual monitoring is slow and error-prone. Our system automatically detects network issues the moment they happen. Outages, anomalies, or unusual traffic spikes trigger instant alerts, so your team does not waste hours identifying problems. Smart algorithms differentiate between minor glitches and critical failures, ensuring only the right issues get flagged. No more missed alerts or delayed responses. Automated detection helps you respond faster, reduce downtime, and protect user experience.
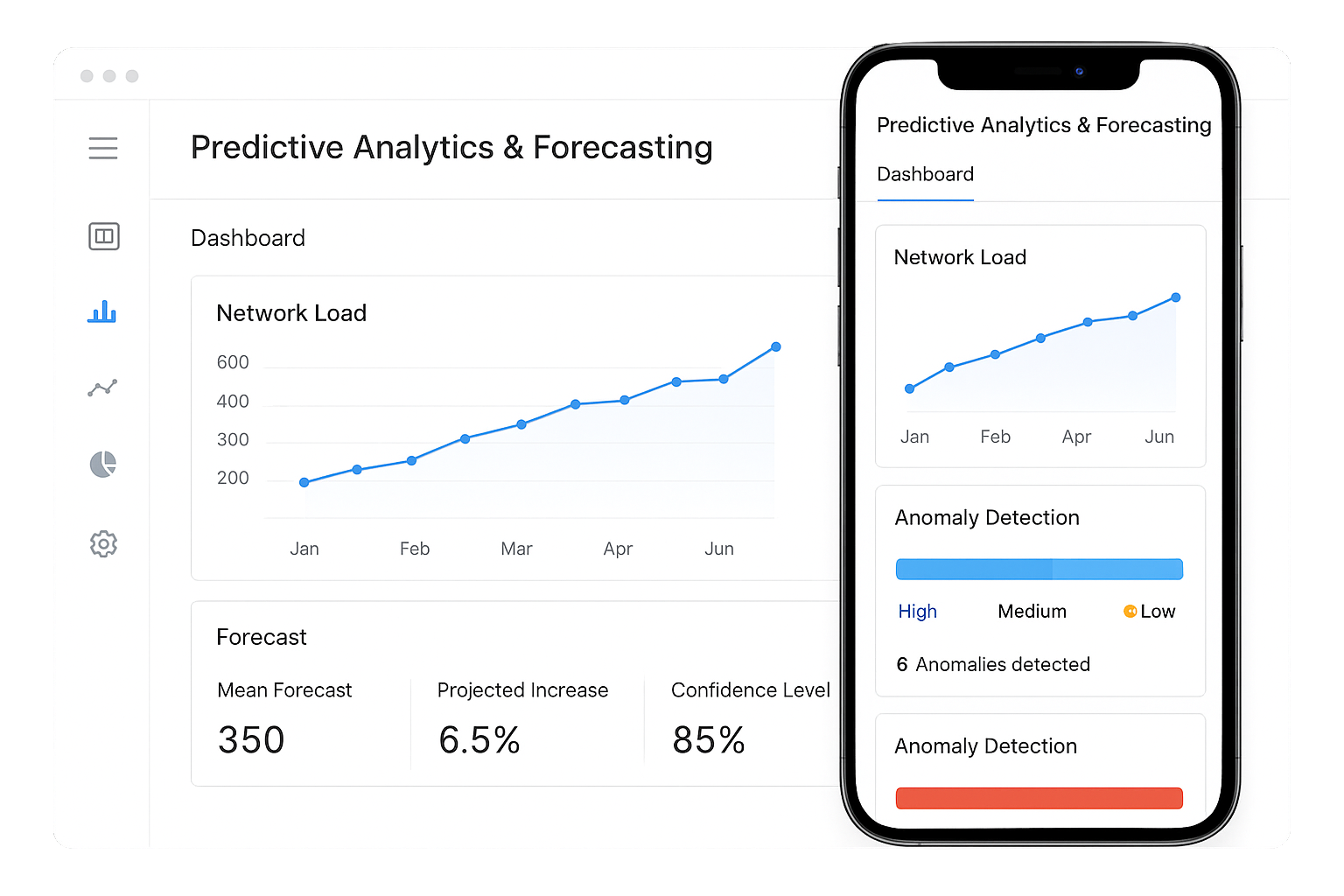
Predictive Analytics & Forecasting
Don not just react - stay one step ahead. Our predictive analytics use AI and machine learning to forecast potential outages, capacity overloads, or device failures. By analyzing historical performance data and usage trends, the system helps you anticipate problems before they escalate. Plan upgrades in advance, avoid bottlenecks, and optimize resources without guesswork. Predictive intelligence turns your NOC from reactive firefighting to proactive strategy. This means fewer surprises, lower costs, and higher uptime.
Predictive Analytics & Forecasting
Don’t just react—stay one step ahead. Our predictive analytics use AI and machine learning to forecast potential outages, capacity overloads, or device failures. By analyzing historical performance data and usage trends, the system helps you anticipate problems before they escalate. Plan upgrades in advance, avoid bottlenecks, and optimize resources without guesswork. Predictive intelligence turns your NOC from reactive firefighting to proactive strategy. This means fewer surprises, lower costs, and higher uptime.
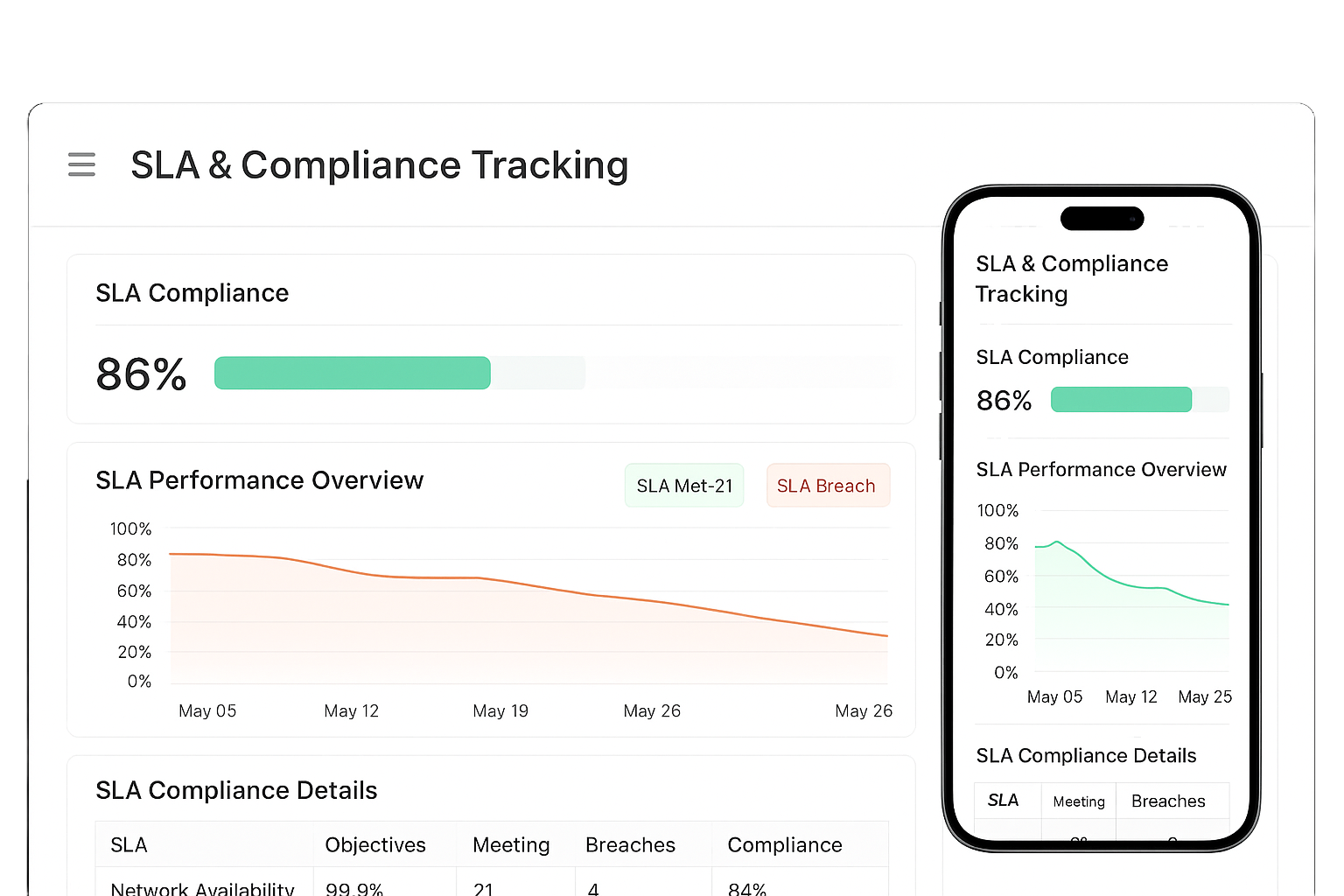
SLA & Compliance Tracking
Meeting SLAs is not optional-it's critical for customer trust and legal obligations. Our NOC automatically tracks uptime, downtime, and performance against your SLA targets. Built-in compliance reporting simplifies audits and provides ready-to-use documentation. You shall always know if you’re on track, where you risk penalties, and how to improve. No manual spreadsheets or complex log reviews needed. SLA dashboards and reports help you maintain accountability and deliver on your promises consistently.
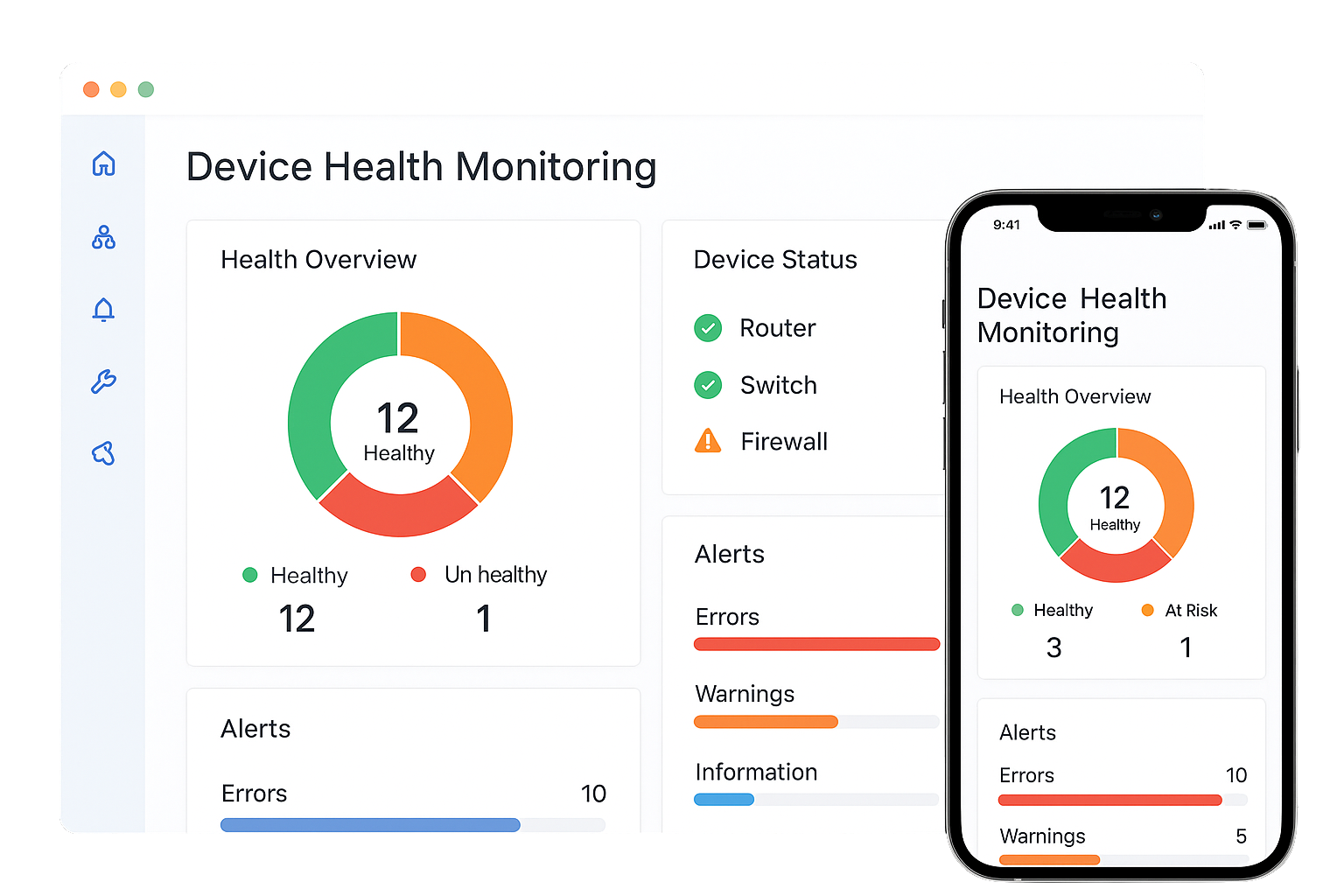
Device Health Monitoring
Every outage starts with an unhealthy device. Our system monitors CPU, memory, disk usage, and temperature across all routers, switches, firewalls, and servers. Get alerts before small issues like overheating or high usage turn into costly downtime. With constant visibility, you can plan maintenance and extend hardware life. Device health monitoring reduces unexpected breakdowns, supports preventive care, and helps your team prioritize critical fixes. Stay ahead of failures and keep your infrastructure reliable.
Build with Freedom on a Visual Canvas
Connect anything and let your data flow freely. Use a cloud-based
API building kit to create workflows that connect any applications.
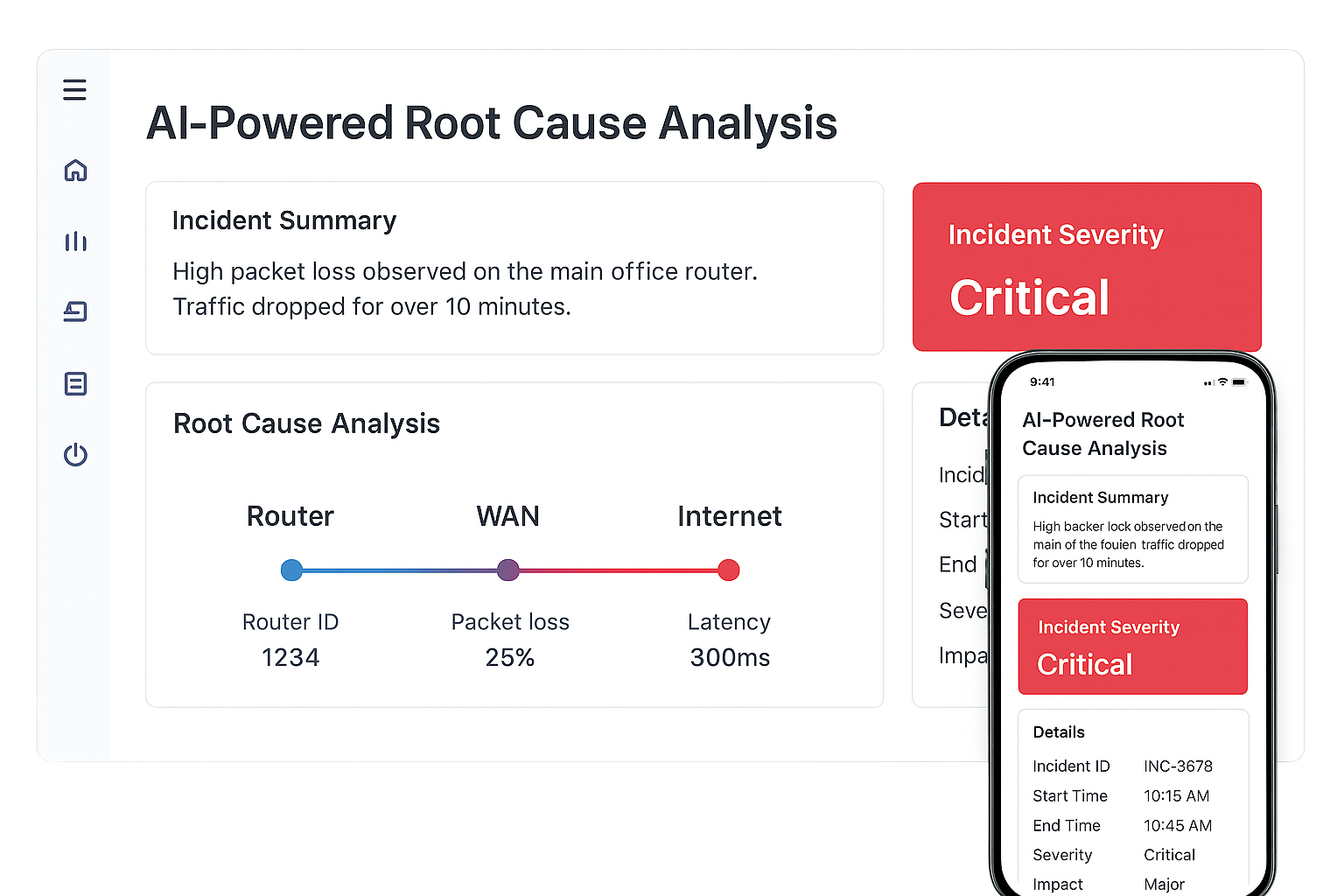
AI-Powered Root Cause Analysis
When incidents hit, the hardest part is finding the actual problem. Our AI-powered root cause analysis filters through the noise of hundreds of alerts to pinpoint what really wrong. Instead of chasing false leads, your team gets directed straight to the source. Whether it is a misconfigured router, a failing switch, or a bandwidth overload, you shall know in minutes. This saves hours of troubleshooting, improves MTTR, and lets your team focus on solutions, not guesswork.
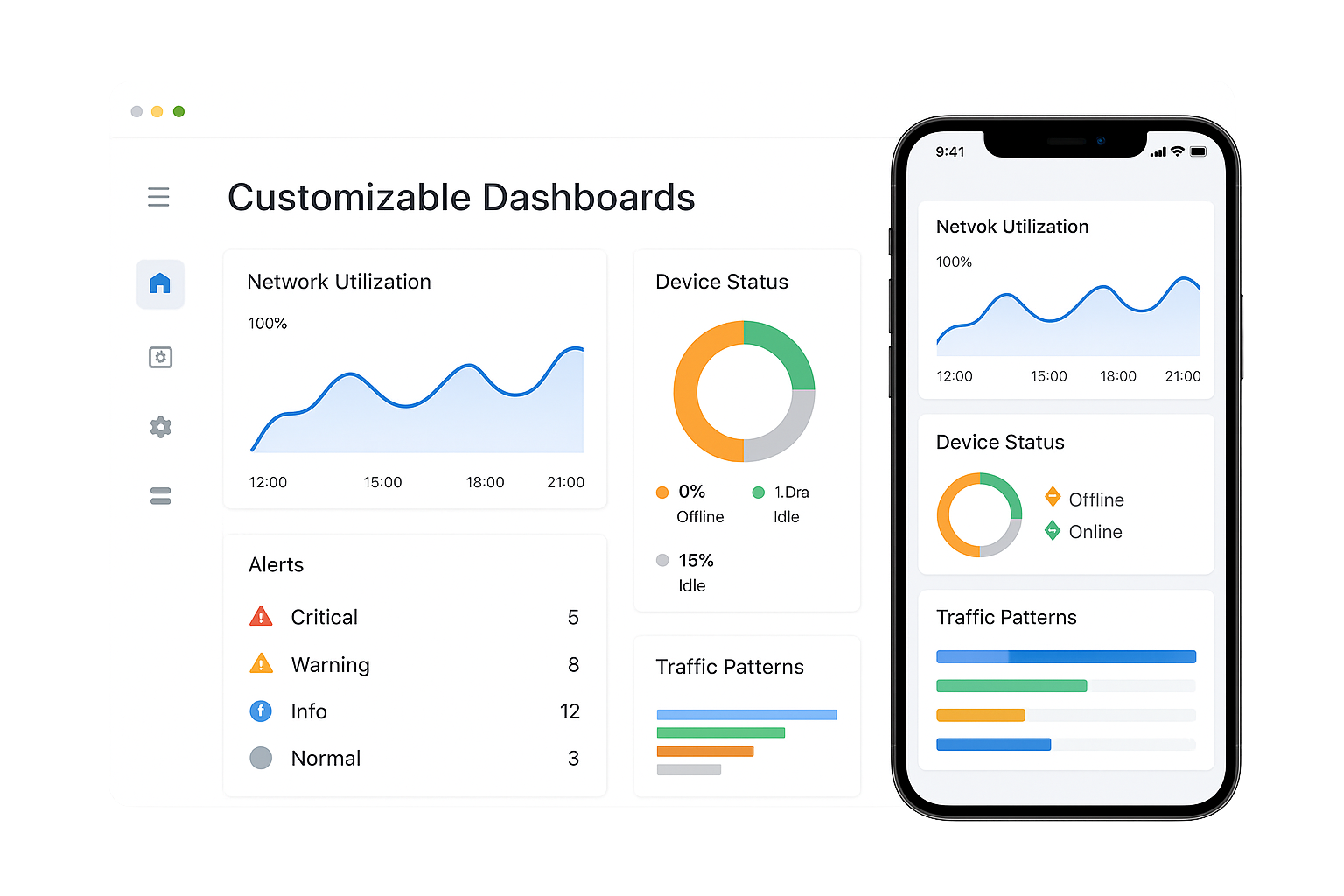
Customizable Dashboards
Not every team cares about the same metrics. Our NOC lets you design dashboards tailored to your priorities-uptime KPIs, SLA performance, security alerts, or device health. Choose what to display, drag and drop widgets, and create views for different departments. Executives can track SLA compliance, while engineers drill into device stats. Flexible dashboards put the right information in front of the right people. That means faster decisions and fewer blind spots.
Customizable Dashboards
Not every team cares about the same metrics. Our NOC lets you design dashboards tailored to your priorities-uptime KPIs, SLA performance, security alerts, or device health. Choose what to display, drag and drop widgets, and create views for different departments. Executives can track SLA compliance, while engineers drill into device stats. Flexible dashboards put the right information in front of the right people. That means faster decisions and fewer blind spots.
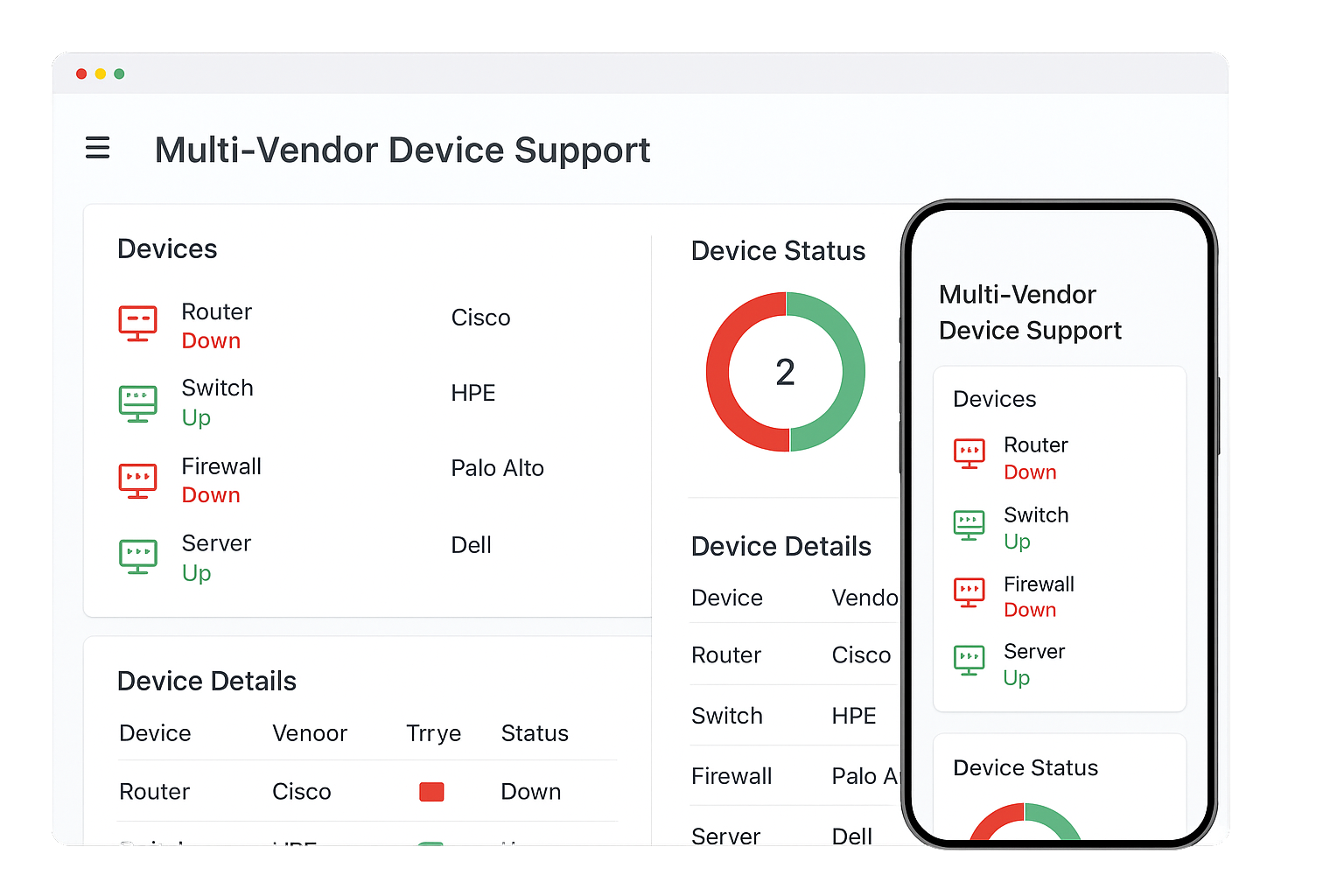
Multi-Vendor Device Support
Your network is built from hardware and software from different vendors and we handle it all. Our NOC integrates with routers, switches, firewalls, and servers across multiple brands without hassle. No need for separate monitoring tools or vendor lock-in. Whether it is Cisco, Juniper, Fortinet, Dell, or others, everything runs under one roof. Multi-vendor support simplifies operations, reduces costs, and streamlines management. You get true visibility across your entire infrastructure, no matter the manufacturer.
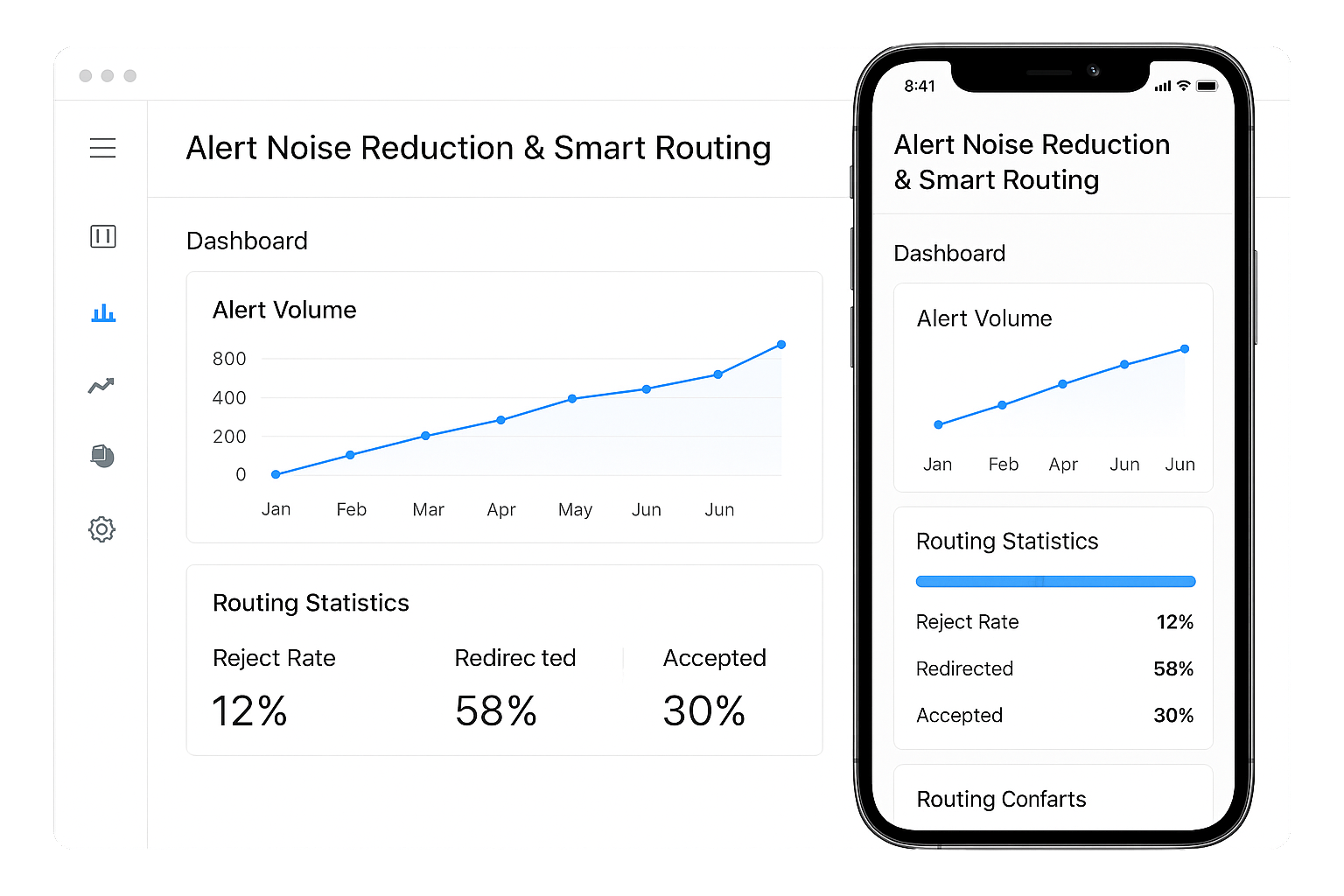
Alert Noise Reduction & Smart Routing
Alert fatigue kills productivity. Our smart filtering engine reduces noise by ignoring duplicate or irrelevant alerts. Critical issues get highlighted, and alerts are routed automatically to the right team member or department. No more spam emails or chasing low-priority warnings. By cutting through the clutter, your team can focus on what matters. Smart routing ensures that incidents never get lost, and the right person gets notified instantly. Faster responses, fewer mistakes, better uptime.
Alert Noise Reduction & Smart Routing
Alert fatigue kills productivity. Our smart filtering engine reduces noise by ignoring duplicate or irrelevant alerts. Critical issues get highlighted, and alerts are routed automatically to the right team member or department. No more spam emails or chasing low-priority warnings. By cutting through the clutter, your team can focus on what matters. Smart routing ensures that incidents never get lost, and the right person gets notified instantly. Faster responses, fewer mistakes, better uptime.
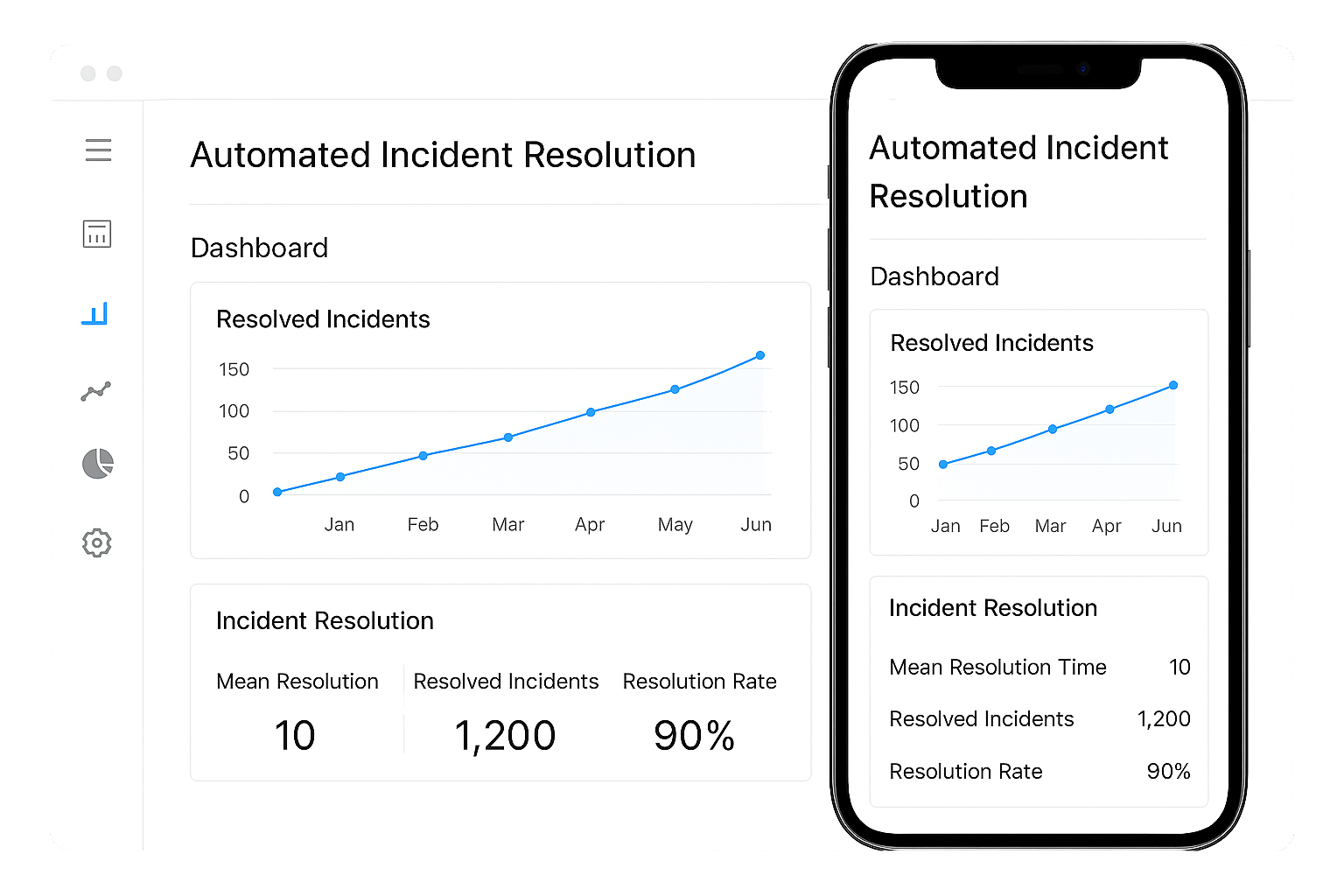
Automated Incident Resolution
Why waste time fixing the same issues again and again? Our platform automates routine incident responses like restarting services, rebooting devices, or triggering failovers. Predefined workflows ensure that common issues resolve instantly without human intervention. This means lower MTTR, fewer escalations, and more time for your team to focus on complex problems. Automation reduces downtime, speeds up recovery, and improves operational efficiency across your entire network.
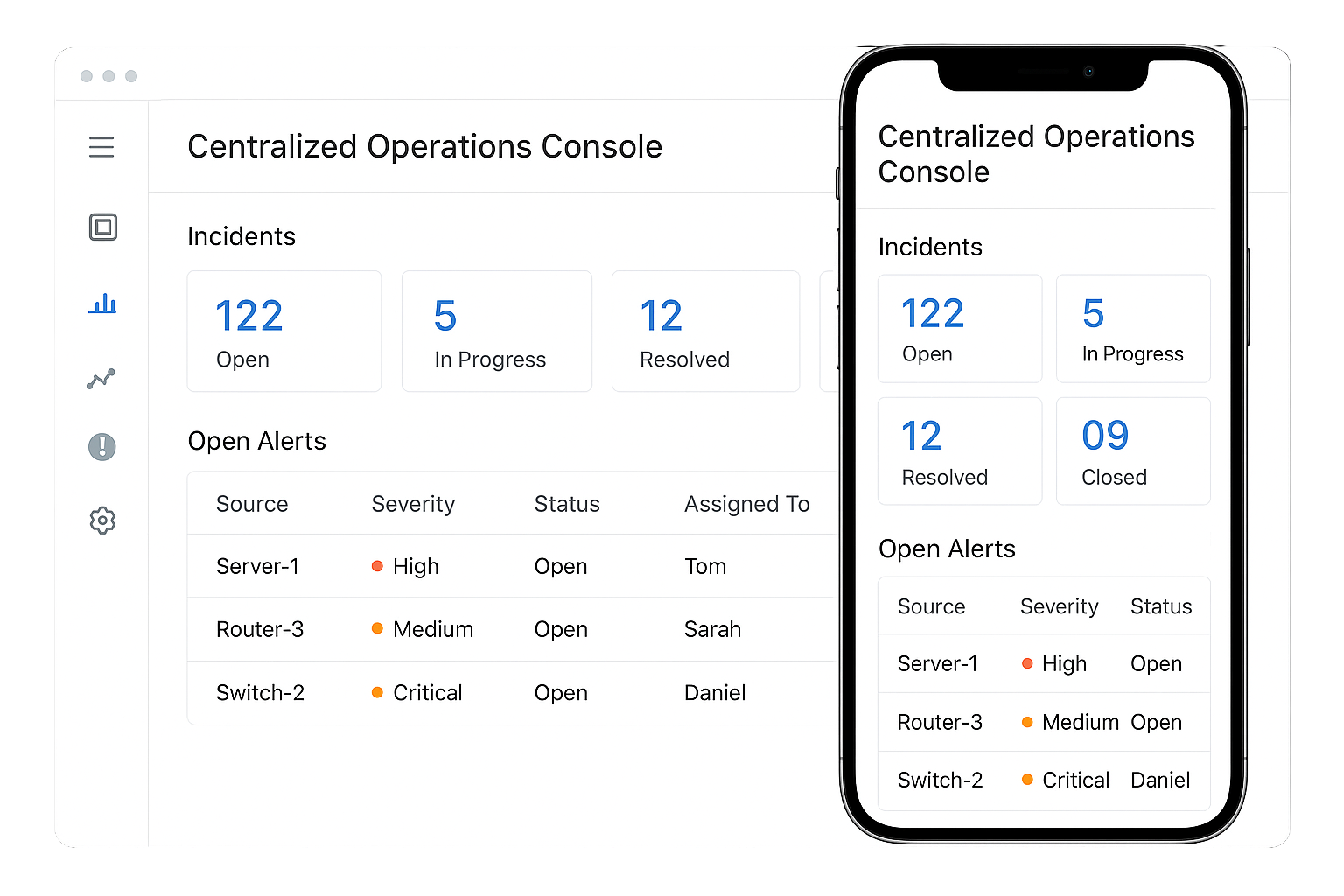
Centralized Operations Console
Stop juggling multiple tools. Our NOC unifies logs, alerts, incidents, and tickets into one centralized console. Everyone from network engineers to IT managers works from the same real-time data. This eliminates silos, speeds up communication, and improves collaboration. With a single source of truth, your team can make faster, smarter decisions. The centralized console becomes the command center for your entire IT operations.
Centralized Operations Console
Stop juggling multiple tools. Our NOC unifies logs, alerts, incidents, and tickets into one centralized console. Everyone from network engineers to IT managers works from the same real-time data. This eliminates silos, speeds up communication, and improves collaboration. With a single source of truth, your team can make faster, smarter decisions. The centralized console becomes the command center for your entire IT operations.
ITSM & Cloud Integrations
Your NOC should work with your existing tools, not replace them. That why we integrate seamlessly with ITSM platforms like ServiceNow and Jira, as well as cloud providers like AWS, Azure, and Google Cloud. Automate ticket creation, update workflows, and link cloud infrastructure monitoring directly into your NOC. These integrations keep your processes smooth, reduce manual work, and ensure your NOC fits perfectly into your IT ecosystem.
Upgrade Your IT Operations: Quisitive
NOC vs The Rest
Feature
24x7 Monitoring
AI-Powered Alerts
Mean Time to Detect
Incident Escalation
Cloud & On-Prem Support
Monthly Reporting
Cost Efficiency
Traditional Monitoring
Limited hours
Basic thresholds
High
Manual
Partial
In House NOC
Yes (costly)
Manual tuning
Medium
Custom
Possible
Internal
High overhead
Quisitive NOC
Yes
Smart noise reduction
Lowest in class
Automated + Human Verified
Full Coverage
Client-Ready
Predictable pricing
"They Call It Magic. We Call It Quisitive."
We had security tools in place, but too many alerts and not enough clarity. Quisitive’s SOC gave us clear visibility and faster response — without adding more work for our team.”

Before Quisitive, we were reacting to threats after they happened. Now, their 24/7 monitoring detects risks early, so we can act before damage occurs.

Meeting compliance was time-consuming and stressful. With Quisitive’s automated reporting, we stay audit-ready all year — with zero last-minute effort.

Got Doubts? Let's Smash 'Em Together
NOC stands for Network Operations Center — a centralized hub where IT teams monitor, manage, and secure an organization’s network infrastructure in real time. Think of it as the nerve center for your digital operations.
A NOC ensures that servers, routers, firewalls, cloud environments, and critical applications are running smoothly 24x7. It uses advanced monitoring tools, automated alerts, and skilled engineers to detect issues like outages, performance bottlenecks, or cyber threats — often before they impact users.
While large enterprises traditionally build in-house NOCs, many businesses today opt for outsourced NOC services to gain enterprise-level reliability without the high costs.
In short:
🔹 NOC = Proactive Network Monitoring
🔹 NOC = Faster Incident Response
🔹 NOC = Maximum Uptime & Security
Whether on-premise or delivered as a managed service, a NOC is essential for any business that depends on a stable, secure, and high-performing IT environment.
A NOC ensures that servers, routers, firewalls, cloud environments, and critical applications are running smoothly 24x7. It uses advanced monitoring tools, automated alerts, and skilled engineers to detect issues like outages, performance bottlenecks, or cyber threats — often before they impact users.
While large enterprises traditionally build in-house NOCs, many businesses today opt for outsourced NOC services to gain enterprise-level reliability without the high costs.
In short:
🔹 NOC = Proactive Network Monitoring
🔹 NOC = Faster Incident Response
🔹 NOC = Maximum Uptime & Security
Whether on-premise or delivered as a managed service, a NOC is essential for any business that depends on a stable, secure, and high-performing IT environment.
NOC as a Service (Network Operations Center as a Service) is a managed IT solution where a dedicated team monitors, manages, and secures your network infrastructure 24x7. It includes real-time monitoring of servers, networks, cloud environments, and applications to ensure maximum uptime, rapid incident response, and proactive threat detection — all delivered by an external expert NOC provider.
This service is ideal for businesses that want enterprise-grade network management without investing in an in-house NOC team.
This service is ideal for businesses that want enterprise-grade network management without investing in an in-house NOC team.
A professional NOC Service offers multiple benefits:
24x7 Network Monitoring: Detect and resolve issues before they impact operations.
Reduced Downtime: Proactive alerts and fast remediation minimize outages and revenue loss.
Improved Security: Continuous surveillance helps identify cyber threats and unauthorized access attempts.
Cost Efficiency: Avoid the high cost of hiring and training an internal NOC team.
Scalability: Easily scale services as your business grows or your IT environment evolves.
Expert Support: Access certified network engineers and advanced monitoring tools.
With NOC as a Service, you gain peace of mind knowing your network is always protected and performing optimally.
24x7 Network Monitoring: Detect and resolve issues before they impact operations.
Reduced Downtime: Proactive alerts and fast remediation minimize outages and revenue loss.
Improved Security: Continuous surveillance helps identify cyber threats and unauthorized access attempts.
Cost Efficiency: Avoid the high cost of hiring and training an internal NOC team.
Scalability: Easily scale services as your business grows or your IT environment evolves.
Expert Support: Access certified network engineers and advanced monitoring tools.
With NOC as a Service, you gain peace of mind knowing your network is always protected and performing optimally.
Businesses of all sizes — especially those relying on IT infrastructure for daily operations — can benefit from NOC Services, including:
Managed Service Providers (MSPs)
Healthcare, finance, and education institutions
E-commerce platforms
SaaS companies
Enterprises with hybrid or multi-cloud environments
If your business depends on network availability, data security, or uninterrupted digital services, basically for those who can't afford downtime, then outsourced NOC services can significantly enhance reliability and performance.
Managed Service Providers (MSPs)
Healthcare, finance, and education institutions
E-commerce platforms
SaaS companies
Enterprises with hybrid or multi-cloud environments
If your business depends on network availability, data security, or uninterrupted digital services, basically for those who can't afford downtime, then outsourced NOC services can significantly enhance reliability and performance.
No — while they complement each other, NOC Service focuses on infrastructure monitoring and backend system management, such as servers, networks, firewalls, and cloud platforms. The NOC proactively identifies and resolves technical issues.
In contrast, Help Desk or IT Support handles end-user issues, like password resets, software problems, or device troubleshooting.
Think of it this way:
🔹 NOC = "Keeping the network alive"
🔹 Help Desk = "Helping users use the network"
Many organizations use both for complete IT coverage.
In contrast, Help Desk or IT Support handles end-user issues, like password resets, software problems, or device troubleshooting.
Think of it this way:
🔹 NOC = "Keeping the network alive"
🔹 Help Desk = "Helping users use the network"
Many organizations use both for complete IT coverage.
Yes! Modern NOC as a Service providers are designed to seamlessly integrate with your current infrastructure — whether on-premise, cloud-based (AWS, Azure, GCP), or hybrid. Using secure APIs, SNMP, agents, or agentless monitoring, the NOC connects to your firewalls, routers, servers, and applications without disruption.
You retain full control while gaining enhanced visibility, alerting, and automated responses — all from a centralized dashboard.
You retain full control while gaining enhanced visibility, alerting, and automated responses — all from a centralized dashboard.
Why Choose Us (Comparison & Pricing)
| Feature Benefit |
In-House NOC |
Outsourced NOC (Generic Vendor) | Traditional Service Providers (Old Model) | Our NOC Services |
|---|---|---|---|---|
| 24/7 Monitoring & Support | Limited coverage, staff fatigue | Available but reactive | Available, but at higher cost | Proactive, real-time monitoring |
| Skilled Expertise | Hard to hire & retain talent | Shared resources | Outdated practices | Certified, dedicated experts |
| Scalability | Expensive infra upgrades | Rigid contracts | Very slow & costly | Flexible, scales with your needs |
| Security & Compliance | Security & Compliances | Basic coverage only | Legacy tools | Advanced compliance-ready SOC+NOC |
| Pricing (Monthly Avg.) | 7-10 Lakhs+ | 4-6 Lakhs | 5-8 Lakhs | 2-3 Lakhs |
| Hidden Costs | High (infra, staff, tools) | Add-ons for upgrades | Very high | None, fully transparent |
| Customization | Low flexibility | Standard packages | One-size-fits-all | Tailored to your business |